Exograph supports pgvector for embeddings


We are happy to introduce Exograph's first integration with AI: embedding support through the pgvector extension. This new feature allows storing and querying vector representations of unstructured data directly in your Postgres database. It complements other Exograph features like access control, indexing, interceptors, and migrations, simplifying the development of AI applications.
Embeddings generated by AI models from OpenAI, Claude, Mistral, and others condense the semantic essence of unstructured data into a small-size vector. The distance between two vectors indicates the similarity of the corresponding data. This capability opens up many possibilities, such as building recommendation systems, classifying data, and implementing AI techniques like RAG (Retrieval Augmented Generation).
Exograph's access control mechanism ensures that the search results are filtered based on the user's access rights. For example, when implementing a RAG application, Exograph ensures that it retrieves and feeds the AI model only the documents the user can access. Access control at the data model level eliminates a source of privacy issues in AI applications.
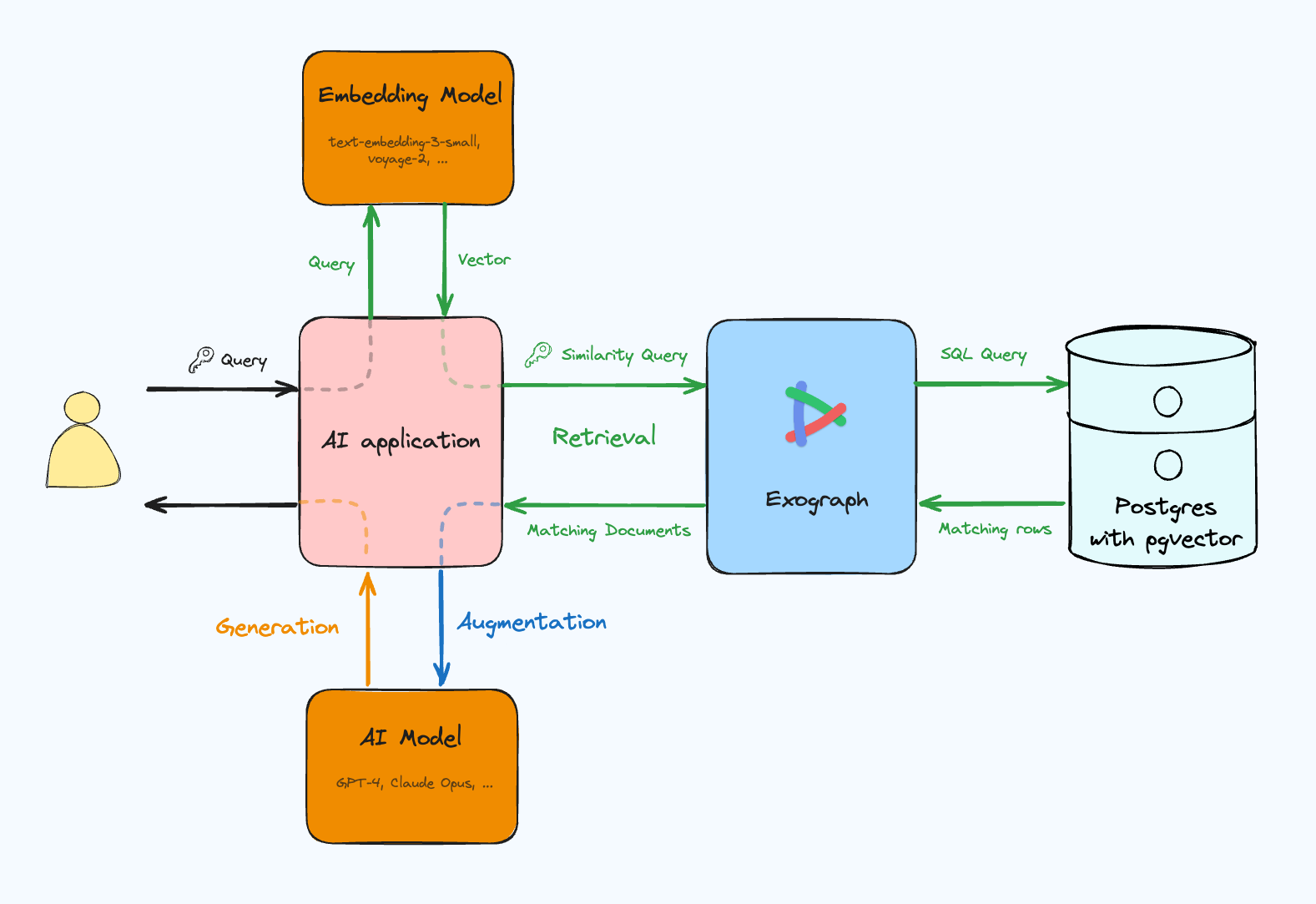
In this blog post, we will explore the concept of embeddings and how Exograph supports it.
Overview
Exograph's embedding support comes through a new Vector type, which uses the pgvector extension internally. This extension enables storing vectors in the database alongside regular data, thus simplifying the integration of embeddings into your application.
Here is an example of a document module with embedding support for the content field:
@postgres
module DocumentModule {
@access(true)
type Document {
@pk id: Int = autoIncrement()
title: String
content: String
contentVector: Vector
}
}
Once you add a field of the Vector type, Exograph takes care of many aspects:
- Creating and migrating the database schema.
- Supporting mutation APIs to store the embeddings in that field.
- Extending retrieval and ordering APIs to use the distance from the given vector.
Let's explore the concept of embeddings and Exograph's support for it.
What is an Embedding?
Picture this: You aim to compile and search through your organization's documents efficiently. Traditional methods fall short; they merely compare strings, missing nuanced connections. For instance, a search for "401k" won't reveal documents mentioning just "Roth"—even though they both deal with the concept of "retirement savings". Enter embeddings.
Embeddings transform data into a numeric vector, capturing its semantic essence.
A mental model behind embeddings is that each dimension represents a semantics (also referred to as a feature or a concept), and the value in a vector represents its closeness to a particular semantics. Consider words like "car", "motorcycle", "dog", and "elephant". If you were to create a vector representation manually, you may define a few semantics and assign a value based on how well the word fits. For instance, you may define the following semantics: "Transportation", "Heavy", and "Animal". You may then assign a value to each word based on how it fits these features. The table below illustrates this concept:
| Word | Semantic Dimension | ||
|---|---|---|---|
| Transportation | Heavy | Animal | |
| Car | 0.9 | 0.8 | 0.1 |
| Motorcycle | 0.8 | 0.5 | 0.1 |
| Dog | 0.1 | 0.1 | 0.9 |
| Elephant | 0.6 | 0.9 | 0.9 |
Here, you created a three-dimensional vector for each word.
Car: [0.9, 0.8, 0.1]
Motorcycle: [0.8, 0.5, 0.1]
Dog: [0.1, 0.1, 0.9]
Elephant: [0.6, 0.9, 0.9]
In practice, you would use an AI model like OpenAI's text-embedding-3-small, which generates the vector based on its training data. The dimension labels in the resulting vector are opaque and lack human-interpretable labels such as "Transportation"; instead, you only have an index and its corresponding value.
Finding similar documents through embeddings involves computing the distance between vectors using metrics like the Euclidean distance or cosine similarity and selecting the closest vectors. For example, if you are looking for documents similar to "Truck", you would compute its vector representation (say, [0.95, 0.9, 0.1]) and find documents with vectors close to it (probably "Car" and "Motorcycle" in the example above).
Using embeddings in your application requires two steps:
- When adding or updating a document, compute its vector representation, store the vector representation, and link it to the document.
- When searching for similar documents, compute the vector representation of the query, find the closest vectors, and retrieve the associated documents. Typically, you'd sort by vector proximity and select the top matches.
Exograph helps with these steps, simplifying AI integration into your applications.
Embeddings in Exograph
Exograph introduces a new type Vector. Fields of this type provide the ability to:
- Store and update the vector representation.
- Filter and order based on the distance from the provided value.
- Specify parameters such as vector size, indexing, and the distance function to compute similarity.
The Vector type feature plays well with the rest of Exograph's capabilities. For example, you can apply access control to your entities, so searching and sorting automatically consider the user's access rights, thus eliminating a source of privacy issues. You can even specify field-level access control to, for example, expose the vector representation only to privileged users.
Let's use the Document model shown earlier but with a few annotations to control a few key aspects:
@postgres
module DocumentModule {
@access(true)
type Document {
@pk id: Int = autoIncrement()
title: String
content: String
@size(1536)
@index
@distanceFunction("l2")
contentVector: Vector?
}
}
First, note that the contentVector field is of the Vector type is marked optional. This supports the typical pattern of initially adding documents without embedding and adding vector representation asynchronously.
Next, note the annotations for the contentVector field to specify a few key aspects:
-
Size: By default, Exograph sets up the vector size to 1536, but you can specify a different size using the
@sizeannotation. Exograph's schema creation and migration will factor in the vector size. -
Indexing: Creating indexes speeds up the search and ordering. When you annotate a
Vectorfield with the@indexannotation, during schema creation (and migration), Exograph sets up a Hierarchical Navigable Small World (HNSW) index. -
Distance function: The core motivation for using vectors is to find vectors similar to a target. There are multiple ways to compute similarity, and based on the field's characteristics, one may be more suitable than others. Since it is a field's characteristic, you can annotate
Vectorfields using the@distanceFunctionannotation to specify the distance function. By default, Exograph uses the "cosine" distance function, but you can specify the "l2" distance function (L2 or Euclidean distance) or "ip" (inner product). Exograph will automatically use this function when filtering and ordering. It will also automatically factor in the distance function while setting up the index.
We use a wide-open access control policy (@access(true)) to keep things simple. In practice, you would use a more restrictive access control policy to ensure only authorized users can access the document's content and vector representation. For example, you could introduce the notion of a "document owner" and allow access only to the owner or users with specific roles (see Evolving Access Control with Exograph for more details). This way, you can ensure that the search results are filtered based on the user's access rights, and when used as context in AI applications, the generated content is based on the user's access rights.
Let's see how to use the Vector type in Exograph from the GraphQL API.
Embedding in GraphQL
Once the model is defined, you can use the Exograph GraphQL API to interact with the model.
To insert a document and its vector representation, you can use the following mutation (updating the vector representation is similar):
mutation ($title: String!, $content: String!, $contentVector: [Float!]!) {
createDocument(
data: { title: $title, content: $content, contentVector: $contentVector }
) {
id
}
}
Note how the Vector field surfaces as a list of floats in the APIs (and not as an opaque custom scalar). This design choice simplifies the integration with the AI models that produce embedding and client code that uses vectors.
Now, we can query our documents. A common query with embedding is to retrieve the top matching documents. You can do it in Exograph with the following query:
query topThreeSimilar($searchVector: [Float!]!) {
documents(
orderBy: { contentVector: { distanceTo: $searchVector, order: ASC } }
limit: 3
) {
id
title
content
}
}
Limiting the number of documents is often sufficient for a typical search or RAG application. However, you can also use the similar operator to filter documents based on the distance from the search vector:
query similar($searchVector: [Float!]!) {
documents(
where: {
contentVector: {
similar: { distanceTo: $searchVector, distance: { lt: 0.5 } }
}
}
) {
id
title
content
}
}
You can combine the orderBy and where clauses to return the top three similar documents only if they are within a certain distance:
query topThreeSimilarDocumentsWithThreshold(
$searchVector: [Float!]!
$threshold: Float!
) {
documents(
where: {
contentVector: {
similar: { distanceTo: $searchVector, distance: { lt: $threshold } }
}
}
orderBy: { contentVector: { distanceTo: $searchVector, order: ASC } }
limit: 3
) {
id
title
content
}
}
You can combine vector-based queries with other fields to filter and order based on other criteria. For example, you can filter based on the document's title along with a similarity filter and order based on the distance from the search vector:
query topThreeSimilarDocumentsWithTitle(
$searchVector: [Float!]!
$title: String!
$threshold: Float!
) {
documents(
where: {
title: { eq: $title }
contentVector: {
similar: { distanceTo: $searchVector, distance: { lt: $threshold } }
}
}
orderBy: { contentVector: { distanceTo: $searchVector, order: ASC } }
limit: 3
) {
id
title
content
}
}
These filtering and ordering capabilities make it easy to focus on the business logic of your application and let Exograph handle the details of querying and sorting based on vector similarity.
What's Next?
This is just the beginning of empowering Exograph applications to leverage the power of AI with minimal effort. We will continue to enhance this feature to support more AI models.
For more detailed documentation, please see the embeddings documentation.
We are excited to see what you build with this new capability. You can reach us on Twitter or Discord with your feedback.