Latency at the edge with Rust/WebAssembly and Postgres: Part 2


In the previous post, we implemented a simple Cloudflare Worker in Rust/WebAssembly connecting to a Neon Postgres database and measured end-to-end latency. Without any pooling, we got a mean response time of 345ms.
The two issues we suspected for the high latency were:
Establishing connection to the database: The worker creates a new connection for each request. Given that a secure connection, it takes 7+ round trips. Not surprisingly, latency is high.
Executing the query: The query method in our code causes the Rust Postgres driver to make two round trips: to prepare the statement and to bind/execute the query. It also sends a one-way message to close the prepared statement.
In this part, we will deal with connection establishment time by introducing a pool. We will fork the driver to deal with multiple round trips (which incidentally also helps with connection pooling). We will also learn a few things about Postgres's query protocol.
The source code with all the examples explored in this post is available on GitHub. With it, you can perform measurements and experiments on your own.
Introducing connection pooling
If the problem is establishing a connection, the solution could be a pool. This way, we can reuse the existing connections instead of creating a new one for each request.
Application-level pooling
Could we use a pooling crate such as deadpool?
While that would be a good option in a typical Rust environment (and Exograph uses it), it is not an option in the Cloudflare Worker environment. A worker is considered stateless and should not maintain any state between requests. Since a pool is a stateful object (holding the connections), it can't be used in a worker. If you try to use it, you will get the following runtime error on every other request:
Error: Cannot perform I/O on behalf of a different request. I/O objects (such as streams, request/response bodies, and others) created in the context of one request handler cannot be accessed from a different request's handler. This is a limitation of Cloudflare Workers which allows us to improve overall performance. (I/O type: WritableStreamSink)
When the client makes the first request, the worker creates a pool and successfully executes the query. For the second request, the worker tries to reuse the pool, but it fails due to the error above, leading to the eviction of the worker by the Cloudflare runtime. For the third request, a fresh worker creates another pool, and the cycle continues.
The error is clear: we cannot use application-level pooling in this environment.
External pooling
Since application-level pooling won't work in this environment, could we try an external pool? Cloudflare provides Hyperdrive for connection pooling (and more, such as query caching). Let's try that.
#[event(fetch)]
async fn main(_req: Request, env: Env, _ctx: Context) -> Result<Response> {
let hyperdrive = env.hyperdrive("todo-db-hyperdrive")?;
let config = hyperdrive
.connection_string()
.parse::<tokio_postgres::Config>()
.map_err(|e| worker::Error::RustError(format!("Failed to parse configuration: {:?}", e)))?;
let host = hyperdrive.host();
let port = hyperdrive.port();
// Same as before
}
Besides how we get the host and port, the rest of the code (to connect to the database and execute the query) remains the same as the one in part 1.
You will need to create a Hyperdrive instance using the following command (replace the connection string with your own):
npx wrangler hyperdrive create todo-db-hyperdrive --caching-disabled --connection-string "postgres://..."
We disable query caching since that will cause skipping most database calls. Due to the empty cache, the first request will hit the database. For subsequent requests (which execute the same SQL query in our setup), Hyperdrive will likely serve them from its cache. We are interested in measuring the latency to include database calls. With caching turned on, the comparison to the baseline would be apples-to-oranges.
For the real-world scenario, you may enable caching to balance database load and freshness of data.
Next, you will need to put the Hyperdrive information in wrangler.toml:
[[hyperdrive]]
binding = "todo-db-hyperdrive"
id = "<your-hyperdrive-id>"
Let's test this worker.
curl <worker-url>
INTERNAL SERVER ERROR
Hmm... that failed.
This is due to an issue with the current Hyperdrive implementation. The support for prepared statements is still new and (currently) works only with caching enabled. I have made the Cloudflare team aware of it. I think this will be fixed soon 🤞.
As things change, I will add updates here.
What's going on? Postgres has two kinds of query protocols:
- Simple query protocol: With this protocol, you must supply the SQL as a string and include any parameter values in the query (for example,
SELECT * FROM todos WHERE id = 1). The driver makes one round trip to execute such a query. - Extended query protocol: With this protocol, you may have the SQL query with placeholders for parameters (for example,
SELECT * FROM todos WHERE id = $1), and its execution requires a preparation step. We will go into detail in the next section.
Let's explore both protocols.
Hyperdrive with the simple query protocol
To explore the simple query protocol, we will use the simple_query method. Since it doesn't allow specifying parameters, we inline them.
#[event(fetch)]
async fn main(_req: Request, env: Env, _ctx: Context) -> Result<Response> {
/// Hyperdrive setup as before
let rows = client
.simple_query("SELECT id, title, completed FROM todos WHERE completed = true")
.await
.map_err(|e| worker::Error::RustError(format!("Failed to query: {:?}", e)))?;
...
}
Does it work and how does this perform?
oha -c 1 -n 100 <worker-url>
Slowest: 0.2871 secs
Fastest: 0.0476 secs
Average: 0.0633 secs
That's more like it! The mean response time is 63ms, a significant improvement over the previous 345ms.
Since the simple query protocol needed only one round trip, Hyperdrive was able to use an existing connection without too much additional logic, so it worked without any issues and performed well.
But... the simple query protocol forces us to use string interpolation to inline the parameters in the query, which is a big no-no in the world of databases due to the risk of SQL injection attacks. So let's not do that!
Hyperdrive with the extended query protocol
Let's go back to the extended query protocol and figure out why Hyperdrive might be struggling with it. As it happens, all external pooling services deal with the same issue; for example, only recently did pgBouncer start to support it.
When using the extended query protocol through query, the driver executes the following steps:
- Prepare: Sends a prepare request. This contains a name for the statement (for example, "s1") and a query with the placeholders for parameters to be provided later (for example, $1, $2 etc.). The server sends back the expected parameter types.
- Bind/execute: Sends the name of the prepared statement and the parameters serialized in the format appropriate for the types. The server looks up the prepared statement by name and executes it with the provided parameters. It sends back the rows.
- Close: Closes the prepared statement to free up the resources on the server. In
tokio-postgres, this is a fire-and-forget operation (doesn't wait for a response).
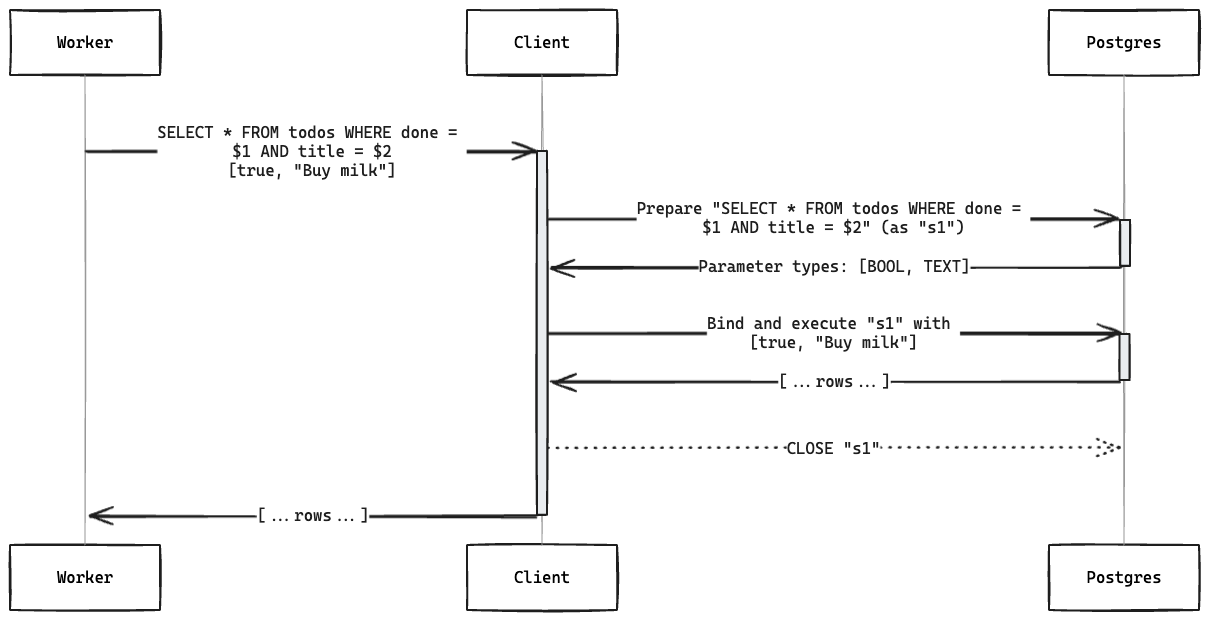
When you add in a connection pool, the driver must invoke the "bind/execute" and "close" with the same connection it used for "prepare". This requires some bookkeeping and is a source of complexity.
What if we combine all three steps into a single network package? This is what Exograph's fork of tokio-postgres (fork, PR) does. The client must specify the parameter values and their types (we no longer perform a round trip to discover parameter types). This way, the driver can serialize the parameters in the correct format in the same network package.
#[event(fetch)]
async fn main(_req: Request, env: Env, _ctx: Context) -> Result<Response> {
/// Hyperdrive setup as before
let rows: Vec<tokio_postgres::Row> = client
.query_with_param_types(
"SELECT id, title, completed FROM todos where completed <> $1",
&[(&true, Type::BOOL)],
)
.await
.map_err(|e| worker::Error::RustError(format!("query_with_param_types: {:?}", e)))?;
...
}
How does this perform?
oha -c 1 -n 100 <worker-url>
Slowest: 0.2883 secs
Fastest: 0.0466 secs
Average: 0.0620 secs
Nice! The mean response time is now 62ms, which matches the simple query protocol (63ms).
Summary
Let's summarize the mean response times for the various configurations:
| Method ➡️ | query | simple_query | query_with_param_types |
|---|---|---|---|
| Pooling ⬇️ | Timing in milliseconds | ||
| None | 345 | 312 | 312 |
| Hyperdrive | see above | 63 | 62 |
With connection pooling through Hyperdrive, we have brought the mean response time by a factor of 5.5 (from 345ms to 62ms)!
The 33ms improvement between query (345ms) and query_with_param_types (312ms) is likely to be due to saving the extra round trip for the "prepare" step but needs further investigation.
The source code is available on GitHub, so you can check this yourself. If you find any improvements or issues, please let me know.
So what should you use? Assuming that the issue with Hyperdrive and query method has been fixed:
- If you don't want to use Hyperdrive, use the
query_with_type_paramsmethod with the forked driver. It does the job in one roundtrip and gives you the best performance without any risk of SQL injection attacks. - If you want to use Hyperdrive:
- If you frequently make the same queries, the
querymethod will likely do better. Hyperdrive may cache the "prepare" part of the step, making subsequent queries faster. - If you make a variety of queries, you can use the
query_with_param_typesmethod. Since you won't execute the same query frequently, Hyperdrive's prepare statement caching is unlikely to help. Instead, this method's fewer round trips will be beneficial.
- If you frequently make the same queries, the
Watch Exograph's blog for more explorations and insights as we ship its Cloudflare Worker support. You can reach us on Twitter or Discord. We would appreciate a star on GitHub!